The hardware and bandwidth for this mirror is donated by dogado GmbH, the Webhosting and Full Service-Cloud Provider. Check out our Wordpress Tutorial.
If you wish to report a bug, or if you are interested in having us mirror your free-software or open-source project, please feel free to contact us at mirror[@]dogado.de.
![]()
@heckmanvytlacil2005e introduced the marginal treatment effect (MTE) to provide a choice-theoretic interpretation for the widely used instrumental variables model of @imbensangrist1994e. The MTE can be used to formally extrapolate from the compliers to estimate treatment effects for other subpopulations.
The ivmte package provides a flexible set of methods for conducting this extrapolation. The package uses the moment-based framework developed by @mogstadsantostorgovitsky2018e, which accommodates both point identification and partial identification (bounds), both parametric and nonparametric models, and allows the user to maintain additional shape constraints.
This vignette is intended as a guide to using ivmte for users already familiar with MTE methods. The key defintions and concepts from that literature are used without further explanation. We have written a paper [@sheatorgovitsky2021wp] that discusses both the MTE methodology and the usage of ivmte, which should be helpful for users unfamiliar with MTE methods. The survey article by @mogstadtorgovitsky2018aroe provides additional theoretical background on MTE methods, including the moment-based implementation used in this module.
ivmte can be installed from CRAN via
install.packages("ivmte")If you have the devtools package, you can install the latest version of the module directly from our GitHub repository via
devtools::install_github("jkcshea/ivmte")Two additional packages are also required for ivmte:
ivmte tries to automatically choose a solver from
those available, with preference being given to Gurobi, CPLEX, and
MOSEK. We have provided the option to use lpSolveAPI
because it appears to be the only interface for solving linear programs
that can be installed solely through install.packages.
However, we strongly recommend using Gurobi, CPLEX, or MOSEK,
since these are actively developed, much more stable, and typically an
order of magnitude faster than lpSolveAPI. A very clear
installation guide for Gurobi can be found here
We will use a subsample of 209133 women from the data used in @angristevans1998taer. The data is included with ivmte and has the following structure.
library(ivmte)
knitr::kable(head(AE, n = 10))| worked | hours | morekids | samesex | yob | black | hisp | other |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 52 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 45 | 1 | 0 | 0 |
| 1 | 35 | 0 | 1 | 49 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 50 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 50 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 51 | 0 | 0 | 0 |
| 1 | 40 | 0 | 0 | 51 | 0 | 0 | 0 |
| 1 | 40 | 0 | 1 | 46 | 0 | 0 | 0 |
| 0 | 0 | 0 | 1 | 45 | 0 | 0 | 0 |
| 1 | 30 | 1 | 0 | 44 | 0 | 0 | 0 |
We will use these variables as follows:
worked is a binary outcome variable that indicates
whether the woman was working.hours is a multivalued outcome variable that measures
the number of hours the woman worked per week.morekids is a binary treatment variable that indicates
whether a woman had more than two children or exactly two children.
samesex is an indicator for whether the woman’s first
two children had the same sex (male-male or female-female). This is used
as an instrument for morekids.yob is the woman’s year of birth (i.e. her age), which
will be used as a conditioning variable.A goal of @angristevans1998taer was to
estimate the causal effect of morekids on either
worked or hours. A linear regression of
worked on morekids yields:
lm(data = AE, worked ~ morekids)
#>
#> Call:
#> lm(formula = worked ~ morekids, data = AE)
#>
#> Coefficients:
#> (Intercept) morekids
#> 0.5822 -0.1423The regression shows that women with three or more children are about 14–15% less likely to be working than women with exactly two children. Is this because children have a negative impact on a woman’s labor supply? Or is it because women with a weaker attachment to the labor market choose to have more children?
@angristevans1998taer address
this question by using samesex as an instrument for
morekids. We expect that samesex is randomly
assigned, so that among women with two or more children, those with weak
labor market attachment are just as likely as those with strong labor
market attachment to have to have two boys or two girls for their first
two children. A regression shows that women whose first two children had
the same sex are also more likely to go on to have a third child:
lm(data = AE, morekids ~ samesex)
#>
#> Call:
#> lm(formula = morekids ~ samesex, data = AE)
#>
#> Coefficients:
#> (Intercept) samesex
#> 0.30214 0.05887Thus, samesex constitutes a potential instrumental
variable for morekids. We can run a simple instrumental
variable regression using the ivreg command from the
AER package.
library("AER")
ivreg(data = AE, worked ~ morekids | samesex )
#>
#> Call:
#> ivreg(formula = worked ~ morekids | samesex, data = AE)
#>
#> Coefficients:
#> (Intercept) morekids
#> 0.56315 -0.08484The coefficient on morekids is smaller in magnitude than
it was in the linear regression of worked on
morekids. This suggests that the linear regression
overstates the negative impact that children have on a woman’s labor
supply. The likely explanation is that women who have more children were
less likely to work anyway.
An important caveat to this reasoning, first discussed by @imbensangrist1994e, is that it
applies only to the group of compliers who would have had a
third child if and only if their first two children were same sex. (This
interpretation requires the so-called monotonicity condition.)
The first stage regression of morekids on
samesex shows that this group comprises less than 6% of the
entire population. Thus, the complier subpopulation is a small and
potentially unrepresentative group of individuals.
Is the relationship between fertility and labor supply for the compliers the same as for other groups? The answer is important if we want to use an instrumental variable estimator to inform policy questions. The purpose of ivmte is to provide a formal framework for answering this type of extrapolation question.
For demonstrating some of the features of ivmte, it
will also be useful to use a simulated dataset. The following code,
which is contained in ./extdata/ivmteSimData.R, generates
some simulated data from a simple DGP. The simulated data is also
included with the package as ./data/ivmteSimData.rda.
set.seed(1)
n <- 5000
u <- runif(n)
z <- rbinom(n, 3, .5)
x <- as.numeric(cut(rnorm(n), 10)) # normal discretized into 10 bins
d <- as.numeric(u < z*.25 + .01*x)
v0 <- rnorm(n) + .2*u
m0 <- 0
y0 <- as.numeric(m0 + v0 + .1*x > 0)
v1 <- rnorm(n) - .2*u
m1 <- .5
y1 <- as.numeric(m1 + v1 - .3*x > 0)
y <- d*y1 + (1-d)*y0
ivmteSimData <- data.frame(y,d,z,x)
knitr::kable(head(ivmteSimData, n = 10))| y | d | z | x |
|---|---|---|---|
| 0 | 0 | 0 | 3 |
| 0 | 0 | 1 | 6 |
| 0 | 0 | 1 | 3 |
| 0 | 0 | 3 | 7 |
| 0 | 1 | 1 | 7 |
| 1 | 0 | 1 | 4 |
| 1 | 0 | 2 | 4 |
| 1 | 0 | 1 | 6 |
| 1 | 0 | 1 | 6 |
| 1 | 1 | 3 | 5 |
The main command of the ivmte package is also called
ivmte. It has the following basic syntax:
library("ivmte")
results <- ivmte(data = AE,
target = "att",
m0 = ~ u + yob,
m1 = ~ u + yob,
ivlike = worked ~ morekids + samesex + morekids*samesex,
propensity = morekids ~ samesex + yob,
noisy = TRUE)Here’s what these required parameters refer to:
data = AE is the usual reference to the data to be
used.target = "att" specifies the target parameter to be the
average treatment on the treated (ATT).m0 and m1 are formulas specifying the MTR
functions for the untreated and treated arms, respectively. The symbol
u in the formula refers to the unobservable latent variable
in the selection equation.ivlike indicates the regressions to be run to create
moments to which the model is fit.propensity specifies a model for the propensity
score.This is what happens when the code above is run:
results <- ivmte(data = AE,
target = "att",
m0 = ~ u + yob,
m1 = ~ u + yob,
ivlike = worked ~ morekids + samesex + morekids*samesex,
propensity = morekids ~ samesex + yob,
noisy = TRUE)
#>
#> Solver: Gurobi ('gurobi')
#>
#> Obtaining propensity scores...
#>
#> Generating target moments...
#> Integrating terms for control group...
#> Integrating terms for treated group...
#>
#> Generating IV-like moments...
#> Moment 1...
#> Moment 2...
#> Moment 3...
#> Moment 4...
#> Independent moments: 4
#>
#> Performing audit procedure...
#> Generating initial constraint grid...
#>
#> Audit count: 1
#> Minimum criterion: 0
#> Obtaining bounds...
#> Violations: 0
#> Audit finished.
#>
#> Bounds on the target parameter: [-0.1028836, -0.07818869]When noisy = TRUE, the ivmte function
indicates its progress in performing a sequence of intermediate
operations. It then runs through an audit procedure to enforce shape
constraints. The audit procedure is described in more detail ahead. After the audit procedure terminates,
ivmte returns bounds on the target parameter, which in this
case is the average treatment on the treated
(target = "att"). These bounds are the primary output of
interest.
The detailed output can be suppressed by passing
noisy = FALSE as an additional parameter. By default,
detailed output is suppressed. Should the user wish to review the
output, it is returned under the entry $messages,
regardless of the value of the noisy parameter.
results <- ivmte(data = AE,
target = "att",
m0 = ~ u + yob,
m1 = ~ u + yob,
ivlike = worked ~ morekids + samesex + morekids*samesex,
propensity = morekids ~ samesex + yob,
noisy = FALSE)
results
#>
#> Bounds on the target parameter: [-0.1028836, -0.07818869]
#> Audit terminated successfully after 1 round
cat(results$messages, sep = "\n")
#>
#> Solver: Gurobi ('gurobi')
#>
#> Obtaining propensity scores...
#>
#> Generating target moments...
#> Integrating terms for control group...
#> Integrating terms for treated group...
#>
#> Generating IV-like moments...
#> Moment 1...
#> Moment 2...
#> Moment 3...
#> Moment 4...
#> Independent moments: 4
#>
#> Performing audit procedure...
#> Generating initial constraint grid...
#>
#> Audit count: 1
#> Minimum criterion: 0
#> Obtaining bounds...
#> Violations: 0
#> Audit finished.
#>
#> Bounds on the target parameter: [-0.1028836, -0.07818869]The required m0 and m1 arguments use the
standard R formula syntax familiar from functions like lm
or glm. However, the formulas involve an unobservable
variable, u, which corresponds to the latent propensity to
take treatment in the selection equation. This variable can be included
in formulas in the same way as other observable variables in the data.
For example,
args <- list(data = AE,
ivlike = worked ~ morekids + samesex + morekids*samesex,
target = "att",
m0 = ~ u + I(u^2) + yob + u*yob,
m1 = ~ u + I(u^2) + I(u^3) + yob + u*yob,
propensity = morekids ~ samesex + yob)
r <- do.call(ivmte, args)
r
#>
#> Bounds on the target parameter: [-0.2950822, 0.1254494]
#> Audit terminated successfully after 3 roundsA restriction that we make for computational purposes is that
u can only appear in polynomial terms (perhaps interacted
with other variables). Thus, the following raises an error
args[["m0"]] <- ~ log(u) + yob
r <- do.call(ivmte, args)
#> Error: The following terms are not declared properly.
#> m0: log(u)
#> The unobserved variable 'u' must be declared as a monomial, e.g. u, I(u^3). The monomial can be interacted with other variables, e.g. x:u, x:I(u^3). Expressions where the unobservable term is not a monomial are either not permissible or will not be parsed correctly, e.g. exp(u), I((x * u)^2). Try to rewrite the expression so that 'u' is only included in monomials.Names other than u can be used for the selection
equation unobservable, but one must remember to pass the option
uname to indicate the new name.
args[["m0"]] <- ~ v + I(v^2) + yob + v*yob
args[["m1"]] <- ~ v + I(v^2) + I(v^3) + yob + v*yob
args[["uname"]] <- "v"
r <- do.call(ivmte, args)
r
#>
#> Bounds on the target parameter: [-0.2950822, 0.1254494]
#> Audit terminated successfully after 3 roundsThere are some limitations regarding the use of factor variables. For
example, the following formula for m1 will trigger an
error.
args[["uname"]] <- ~ "u"
args[["m0"]] <- ~ u + yob
args[["m1"]] <- ~ u + factor(yob)55 + factor(yob)60However, one can work around this in a natural way.
args[["m1"]] <- ~ u + (yob == 55) + (yob == 60)
r <- do.call(ivmte, args)
r
#>
#> Bounds on the target parameter: [-0.1028836, -0.07818869]
#> Audit terminated successfully after 1 roundIn addition to global polynomials in u,
ivmte also allows for polynomial splines in u
using the keyword uSplines. For example,
args <- list(data = AE,
ivlike = worked ~ morekids + samesex + morekids*samesex,
target = "att",
m0 = ~ u + uSplines(degree = 1, knots = c(.2, .4, .6, .8)) + yob,
m1 = ~ uSplines(degree = 2, knots = c(.1, .3, .5, .7))*yob,
propensity = morekids ~ samesex + yob)
r <- do.call(ivmte, args)
r
#>
#> Bounds on the target parameter: [-0.4545814, 0.3117817]
#> Audit terminated successfully after 2 roundsThe degree refers to the polynomial degree, so that
degree = 1 is a linear spline, and degree = 2
is a quadratic spline. Constant splines, which have an important role in
some of the theory developed by @mogstadsantostorgovitsky2018e,
can be implemented with degree = 0. The vector
knots indicates the piecewise regions for the spline. Note
that 0 and 1 are always automatically included
as knots, so that only the interior knots need to be
specified.
One can also require the MTR functions to satisfy the following nonparametric shape restrictions.
m0.lb, m0.ub, m1.lb, and
m1.ub, which all take scalar values. In order to produce
non-trivial bounds in cases of partial identification,
m0.lb and m1.lb are by default set to the
smallest value of the response variable (which is inferred from
ivlike) that is observed in the data, while
m0.ub and m1.ub are set to the largest
value.m1 - m0, by
setting mte.lb and mte.ub. By default, these
are set to the values logically implied by the values for
m0.lb, m0.ub, m1.lb, and
m1.ub.u for each value
of the other observed variables, via the parameters m0.dec,
m0.inc, m1.dec, m1.inc, which all
take boolean values.u, via the
parameters mte.dec and mte.inc.Here is an example with monotonicity restrictions:
args <- list(data = AE,
ivlike = worked ~ morekids + samesex + morekids*samesex,
target = "att",
m0 = ~ u + uSplines(degree = 1, knots = c(.2, .4, .6, .8)) + yob,
m1 = ~ uSplines(degree = 2, knots = c(.1, .3, .5, .7))*yob,
m1.inc = TRUE,
m0.inc = TRUE,
mte.dec = TRUE,
propensity = morekids ~ samesex + yob)
r <- do.call(ivmte, args)
r
#>
#> Bounds on the target parameter: [-0.09769381, 0.09247149]
#> Audit terminated successfully after 1 roundThe shape restrictions in the previous section are enforced by adding constraints to a linear program. It is difficult in general to ensure that a function satisfies restrictions such as boundedness or monotonicity, even if that function is known to be a polynomial. This difficulty is addressed in ivmte through an auditing procedure.
The auditing procedure is based on two grids: A relatively small constraint grid, and a relatively large audit grid. The MTR functions (and implied MTE function) are made to satisfy the specified shape restrictions on the constraint grid by adding constraints to the linear programs. While this ensures that the MTR functions satisfy the shape restrictions on the constraint grid, it does not ensure that they satisfy the restrictions “everywhere.” Thus, after solving the programs, we evaluate the solution MTR functions on the large audit grid, which is relatively inexpensive computationally. If there are points in the audit grid at which the solution MTRs violate the desired restrictions, then we add some of these points to the constraint grid and repeat the procedure. The procedure ends (the audit is passed), when the solution MTRs satisfy the constraints over the entire audit grid.
There are certain parameters that can be used to tune the audit
procedure: The number of initial points in the constraint grid
(initgrid.nu and initgrid.nx), the number of
points in the audit grid (audit.nu and
audit.nx), the maximum number of points that are added from
the audit grid to the constraint grid (audit.add) for each
constraint, and the maximum number of times the audit procedure is
repeated before giving up (audit.max). We have tried to
choose defaults for these parameters that should be suitable for most
applications. However, if ivmte takes a very long time to
run, one might want to try adjusting these parameters. Also, if
audit.max is hit, which should be unlikely given the
default settings, one should either adjust the settings or examine the
audit.grid$violations field of the returned results to see
the extent to which the shape restrictions are not satisfied.
The target parameter is the object the researcher wants to know. ivmte has built-in support for conventional target parameters and a class of generalized LATEs. It also has a system that allows users to construct their own target parameters by defining the associated weights.
The target parameter can be set to the average treatment effect
(ATE), average treatment on the treated (ATT), or the average treatment
on the untreated by setting target to ate,
att, or atu, respectively. For example:
args <- list(data = AE,
ivlike = worked ~ morekids + samesex + morekids*samesex,
target = "att",
m0 = ~ u + I(u^2) + yob + u*yob,
m1 = ~ u + I(u^2) + I(u^3) + yob + u*yob,
propensity = morekids ~ samesex + yob)
r <- do.call(ivmte, args)
r
#>
#> Bounds on the target parameter: [-0.2950822, 0.1254494]
#> Audit terminated successfully after 3 rounds
args[["target"]] <- "ate"
r <- do.call(ivmte, args)
r
#>
#> Bounds on the target parameter: [-0.375778, 0.1957841]
#> Audit terminated successfully after 1 roundLATEs can be set as target parameters by passing
target = late and including named lists called
late.from and late.to. The named lists should
contain variable name and value pairs, where the variable names must
also appear in the propensity score formula. Typically, one would choose
instruments for these variables, although ivmte will let
you include control variables as well. We demonstrate this using the
simulated data.
args <- list(data = ivmteSimData,
ivlike = y ~ d + z + d*z,
target = "late",
late.from = c(z = 1),
late.to = c(z = 3),
m0 = ~ u + I(u^2) + I(u^3) + x,
m1 = ~ u + I(u^2) + I(u^3) + x,
propensity = d ~ z + x)
r <- do.call(ivmte, args)
r
#>
#> Bounds on the target parameter: [-0.6931532, -0.4397993]
#> Audit terminated successfully after 2 roundsWe can condition on covariates in the definition of the LATE by
adding the named list late.X as follows.
args[["late.X"]] = c(x = 2)
r <- do.call(ivmte, args)
r
#>
#> Bounds on the target parameter: [-0.8419396, -0.2913049]
#> Audit terminated successfully after 2 rounds
args[["late.X"]] = c(x = 8)
r <- do.call(ivmte, args)
r
#>
#> Bounds on the target parameter: [-0.7721625, -0.3209851]
#> Audit terminated successfully after 2 roundsivmte also provides support for generalized LATEs,
i.e. LATEs where the intervals of u that are being
considered may or may not correspond to points in the support of the
propensity score. These objects are useful for a number of extrapolation
purposes, see e.g. @mogstadsantostorgovitsky2018e.
They are set with target = "genlate" and the additional
scalars genlate.lb and genlate.ub. For
example,
args <- list(data = ivmteSimData,
ivlike = y ~ d + z + d*z,
target = "genlate",
genlate.lb = .2,
genlate.ub = .4,
m0 = ~ u + I(u^2) + I(u^3) + x,
m1 = ~ u + I(u^2) + I(u^3) + x,
propensity = d ~ z + x)
r <- do.call(ivmte, args)
args[["genlate.ub"]] <- .41
r <- do.call(ivmte, args)
args[["genlate.ub"]] <- .42
r <- do.call(ivmte, args)
r
#>
#> Bounds on the target parameter: [-0.7504255, -0.3182317]
#> Audit terminated successfully after 2 roundsGeneralized LATEs can also be made conditional-on-covariates by
passing late.X:
args[["late.X"]] <- c(x = 2)
r <- do.call(ivmte, args)
r
#>
#> Bounds on the target parameter: [-0.867551, -0.2750135]
#> Audit terminated successfully after 2 roundsSince there are potentially a large and diverse array of target parameters that a researcher might be interested in across various applications, the ivmte package also allows the specification of custom target parameters. This is done by specifying the two weighting functions for the target parameters.
To facilitate computation, these functions must be expressible as
constant splines in u. For the untreated weights, the knots
of the spline are specified with target.knots0 and the
weights to place in between each knot is given by
target.weight0. Since the weighting functions might depend
on both the instrument and other covariates, both
target.knots0 and target.weight0 should be
lists consisting of functions or scalars. (A scalar is interpreted as a
constant function.) If the lists include any functions, then the
arguments of the functions must be the names of the variables that the
knots or weights depend on. These variables do not have to be a part of
the model, but must be included in the data provided to
ivmte. Specifying the treated weights works the same way
but with target.knots1 and target.weight1. If
the target option is passed along with the custom weights,
an error is returned.
Here is an example of using custom weights to replicate the conditional LATE from above.
pmodel <- r$propensity$model # returned from the previous run of ivmte
xeval = 2 # x = xeval is the group that is conditioned on
px <- mean(ivmteSimData$x == xeval) # probability that x = xeval
z.from = 1
z.to = 3
weight1 <- function(x) {
if (x != xeval) {
return(0)
} else {
xz.from <- data.frame(x = xeval, z = z.from)
xz.to <- data.frame(x = xeval, z = z.to)
p.from <- predict(pmodel, newdata = xz.from, type = "response")
p.to <- predict(pmodel, newdata = xz.to, type = "response")
return(1 / ((p.to - p.from) * px))
}
}
weight0 <- function(x) {
return(-weight1(x))
}
## Define knots (same for treated and control)
knot1 <- function(x) {
xz.from <- data.frame(x = x, z = z.from)
p.from <- predict(pmodel, newdata = xz.from, type = "response")
return(p.from)
}
knot2 <- function(x) {
xz.to <- data.frame(x = x, z = z.to)
p.to <- predict.glm(pmodel, newdata = xz.to, type = "response")
return(p.to)
}
args <- list(data = ivmteSimData,
ivlike = y ~ d + z + d*z,
target.knots0 = c(knot1, knot2),
target.knots1 = c(knot1, knot2),
target.weight0 = c(0, weight0, 0),
target.weight1 = c(0, weight1, 0),
m0 = ~ u + I(u^2) + I(u^3) + x,
m1 = ~ u + I(u^2) + I(u^3) + x,
propensity = d ~ z + x)
r <- do.call(ivmte, args)
r
#>
#> Bounds on the target parameter: [-0.8419396, -0.2913049]
#> Audit terminated successfully after 2 roundsThe knot specification here is the same for both the treated and
untreated weights. It specifies two knots that depend on whether
x == 2, so that there are four knots total when accounting
for 0 and 1, which are always included automatically. These four knots
divide the interval between 0 and 1 into three regions. The first region
is from 0 to the value of the propensity score when evaluated at
x and z.from. The second region is between
this point and the propensity score evaluated at x and
z.to. The third and final region is from this point up to
1.
Since the knot specification creates three regions, three weight
functions must be passed. Here, the weights in the first and third
regions are set to 0 regardless of the value of x by just
passing a scalar 0. The weights in the second region are
only non-zero when x == 2, in which case they are equal to
the inverse of the distance between the second and third knot points.
Thus, the weighting scheme applies equal weight to compliers with
x == 2, and zero weight to all others. As expected, the
resulting bounds match those that we computed above using
target == late.
The IV–like estimands refer to the moments in the data that are used to fit the model. In ivmte these are restricted to be only moments that can be expressed as the coefficient in either a linear regression (LR) or two stage least squares (TSLS) regression of the outcome variable on the other variables in the dataset.
There are three aspects that can be changed, which we discuss in order subsequently. First, one can specify one or multiple LR and TSLS formulas from which moments are used. By default, all moments from each formula are used. Second, one can specify that only certain moments from a formula are used. Third, one can specify a subset of the data on which the formula is run, which provides an easy way to nonparametrically condition on observables.
The required ivlike option expects a list of R formulas.
All of our examples up to now have had a single LR. However, one can
include multiple LRs, as well as TSLS regressions using the
| syntax familiar from the AER package.
Each formula must have the same variable on the left-hand side, which is
how the outcome variable gets inferred. For example,
args <- list(data = ivmteSimData,
ivlike = c(y ~ (z == 1) + (z == 2) + (z == 3) + x,
y ~ d + x,
y ~ d | z),
target = "ate",
m0 = ~ uSplines(degree = 1, knots = c(.25, .5, .75)) + x,
m1 = ~ uSplines(degree = 1, knots = c(.25, .5, .75)) + x,
propensity = d ~ z + x)
r <- do.call(ivmte, args)
#> Warning: The following IV-like specifications do not include the treatment
#> variable: 1. This may result in fewer independent moment conditions than
#> expected.
r
#>
#> Bounds on the target parameter: [-0.6427017, -0.3727193]
#> Audit terminated successfully after 1 roundThere are 10 moments being fit in this specification. Five of these
moments correspond to the constant term, the coefficients on the three
dummies (z == 1), (z == 2) and
(z == 3), and the coefficient on x from the
first linear regression. There are three more coefficients from the
second regression of y on d, x,
and a constant. Finally, there are two moments from the TSLS (simple IV
in this case) regression of y on d and a
constant, using z and a constant as instruments.
The default behavior of ivmte is to use all of the
moments from each formula included in ivlike. There are
reasons one might not want to do this, such as if certain moments are
estimated poorly (i.e. with substantial statistical error). For more
information, see the discussions in @mogstadsantostorgovitsky2018e
and @mogstadtorgovitsky2018aroe.
One can tell ivmte to only include certain moments and
not others by passing the components option. This option
expects a list of the same length as the list passed to
ivlike. Each component of the list is itself a list that
contains the variable names for the coefficients to be included from
that formula. The list should be declared using the l
function, which is a generalization of the list function.
The l function allows the user to list variables and
expressions without having to enclose them by quotation marks. For
example, the following includes the coefficients on the intercept and
x from the first formula, the coefficient on d
from the second formula, and all coefficients in the third formula.
args[["components"]] <- l(c(intercept, x), c(d), )
r <- do.call(ivmte, args)
r
#>
#> Bounds on the target parameter: [-0.6865291, -0.2573525]
#> Audit terminated successfully after 1 roundNote that intercept is a reserved word that is used to
specify the coefficient on the constant term. If the function
list is used to pass the components option, an
error will follow.
args[["components"]] <- list(c(intercept, x), c(d), )
#> Error in eval(expr, envir, enclos): object 'intercept' not found
args[["components"]] <- list(c("intercept", "x"), c("d"), "")
r <- do.call(ivmte, args)
#> Error in terms.formula(fi, ...): invalid model formula in ExtractVarsThe formulas can be run conditional on certain subgroups by adding
the subset option. This option expects a list of logical
statements with the same length as ivlike declared using
the l function. One can use the entire data by leaving the
statement blank, or inserting a tautology such as 1 == 1.
For example, the following would run the first regression only on
observations with x less than or equal to 9, the second
regression on the entire sample, and the third (TSLS) formula only on
those observations that have z equal to 1 or 3.
args <- list(data = ivmteSimData,
ivlike = c(y ~ z + x,
y ~ d + x,
y ~ d | z),
subset = l(x <= 9, 1 == 1, z %in% c(1,3)),
target = "ate",
m0 = ~ uSplines(degree = 3, knots = c(.25, .5, .75)) + x,
m1 = ~ uSplines(degree = 3, knots = c(.25, .5, .75)) + x,
propensity = d ~ z + x)
r <- do.call(ivmte, args)
#> Warning: The following IV-like specifications do not include the treatment
#> variable: 1. This may result in fewer independent moment conditions than
#> expected.
r
#>
#> Bounds on the target parameter: [-0.6697228, -0.3331582]
#> Audit terminated successfully after 2 roundsThe procedure implemented by ivmte requires first
estimating the propensity score, that is, the probability that the
binary treatment variable is 1, conditional on the instrument and other
covariates. This must be specified with the propensity
option, which expects a formula. The treatment variable is inferred to
be the variable on the left-hand side of the propensity.
The default is to estimate the formula as a logit model via the
glm command, but this can be changed to
"linear" or "probit" with the
link option.
results <- ivmte(data = AE,
target = "att",
m0 = ~ u + yob,
m1 = ~ u + yob,
ivlike = worked ~ morekids + samesex + morekids*samesex,
propensity = morekids ~ samesex + yob,
link = "probit")
results
#>
#> Bounds on the target parameter: [-0.100781, -0.0825274]
#> Audit terminated successfully after 1 roundBy default, ivmte will determine if the model is point
identified. This typically occurs when ivlike,
components and subset are such that they have
more (non-redundant) components than there are free parameters in
m0 and m1. If the model is point identified,
then the bounds will typically shrink to a point. The ivmte
function will then estimate the target parameter using quadratic loss
and the optimal two-step GMM weighting matrix for moments. If the model
is known to be point identified beforehand, one can include the option
point = TRUE to ensure the target parameter is estimated
this way. One can additionally pass point.eyeweight = TRUE
to estimate the target parameter using identity weighting.
args <- list(data = ivmteSimData,
ivlike = y ~ d + factor(z),
target = "ate",
m0 = ~ u,
m1 = ~ u,
propensity = d ~ factor(z),
point = TRUE)
r <- do.call(ivmte, args)
r
#>
#> Point estimate of the target parameter: -0.5389508If ivmte determines that the model is not point
identified or the user passes point = FALSE, then the
bounds on the target parameter will be estimated. However, the user may
still pass point = FALSE even though there are more
(non-redundant) moments than free parameters in m0 and
m1. The bounds will collapse to a point, but may differ
from the case where point = TRUE. The reason is that
ivmte uses absolute deviation loss instead of quadratic
loss when point = FALSE. To demonstrate this, the example
below sets the tuning parameter criterion.tol = 0 so that
the bounds indeed collapse to a point (see @mogstadsantostorgovitsky2018e
for more detail).
args$point <- FALSE
args$criterion.tol <- 0
r <- do.call(ivmte, args)
r
#>
#> Bounds on the target parameter: [-0.5349027, -0.5349027]
#> Audit terminated successfully after 1 roundOne should use point = TRUE if the model is point
identified, since it computes confidence intervals and specification
tests (discussed ahead) in a well-understood way.
The ivmte command does provide functionality for
constructing confidence regions, although this is turned off by default,
since it can be computationally expensive. To turn it on, set
bootstraps to be a positive integer. The confidence
intervals are stored under $bounds.ci.
r <- ivmte(data = AE,
target = "att",
m0 = ~ u + yob,
m1 = ~ u + yob,
ivlike = worked ~ morekids + samesex + morekids*samesex,
propensity = morekids ~ samesex + yob,
bootstraps = 50)
summary(r)
#>
#> Bounds on the target parameter: [-0.1028836, -0.07818869]
#> Audit terminated successfully after 1 round
#> MTR coefficients: 6
#> Independent/total moments: 4/4
#> Minimum criterion: 0
#> Solver: Gurobi ('gurobi')
#>
#> Bootstrapped confidence intervals (backward):
#> 90%: [-0.1767266, 0.01163401]
#> 95%: [-0.1877661, 0.0125208]
#> 99%: [-0.1879194, 0.05562988]
#> p-value: 0.16
#> Number of bootstraps: 50Other options relevent to confidence region construction are
bootstraps.m, which indicates the number of observations to
draw from the sample on each bootstrap replication, and
bootstraps.replace to indicate whether these observations
should be drawn with or without replacement. The default is to set
bootstraps.m to the sample size of the observed data with
bootstraps.replace = TRUE. This corresponds to the usual
nonparametric bootstrap. Choosing bootstraps.m to be
smaller than the sample size and setting bootstraps.replace
to be TRUE or FALSE corresponds to the “m out
of n” bootstrap or subsampling, respectively. Regardless of these
settings, two types of confidence regions are constructed following the
terminology of @andrewshan2009ej; see @sheatorgovitsky2021wp for
more detail, references, and important theoretical caveats to the
procedures. While the summary output displays only the
backward confidence region, both forward and backward confidence regions
are stored under $bounds.ci.
r$bounds.ci
#> $backward
#> lb.backward ub.backward
#> 0.9 -0.1767266 0.01163401
#> 0.95 -0.1877661 0.01252080
#> 0.99 -0.1879194 0.05562988
#>
#> $forward
#> lb.forward ub.forward
#> 0.9 -0.2013875 -0.010580678
#> 0.95 -0.2021541 -0.007122401
#> 0.99 -0.2473285 -0.002190831The bootstrapped bounds are returned and stored in
r$bounds.bootstraps, and can be used to plot the
distribution of bound estimates.
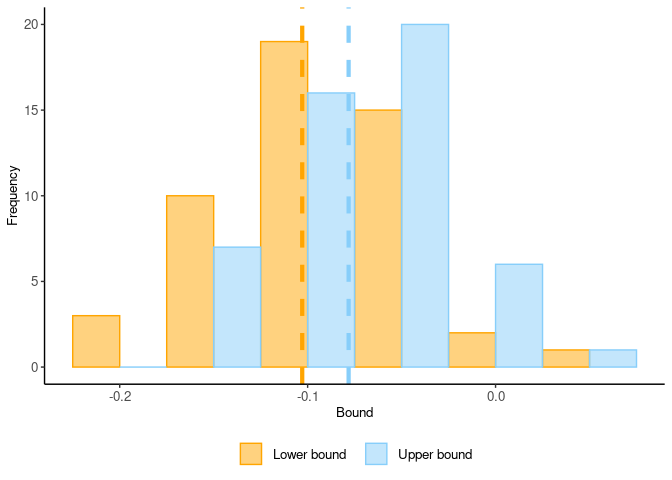
head(r$bounds.bootstrap)
#> lower upper
#> 1 -0.176726565 -0.13140944
#> 2 -0.079414585 -0.04838939
#> 3 -0.004379649 0.01163401
#> 4 -0.126917750 -0.09350509
#> 5 -0.110911453 -0.09289715
#> 6 -0.101183496 -0.08202556The dashed lines in the figure below indicate the bounds obtained from the original sample.
Confidence regions can also be constructed when
point == TRUE in a similar way. The bootstrapped point
estimates are returned and stored in
r$point.estimate.bootstraps.
args <- list(data = AE,
target = "att",
m0 = ~ u,
m1 = ~ u,
ivlike = worked ~ morekids + samesex + morekids*samesex,
propensity = morekids ~ samesex,
point = TRUE,
bootstraps = 50)
r <- do.call(ivmte, args)
summary(r)
#>
#> Point estimate of the target parameter: -0.09160436
#> MTR coefficients: 4
#> Independent/total moments: 4/4
#>
#> Bootstrapped confidence intervals (nonparametric):
#> 90%: [-0.1521216, -0.02213206]
#> 95%: [-0.1595378, -0.01554401]
#> 99%: [-0.2023271, -0.002062735]
#> p-value: 0.02
#> Number of bootstraps: 50The p-value reported in both cases is for the null hypothesis that
the target parameter is equal to 0, which we infer here by finding the
largest confidence region that does not contain 0. By default,
ivmte returns 99%, 95%, and 90% confidence intervals. This
can be changed with the levels option.
The moment-based framework implemented by ivmte is
amenable to specification tests. These tests are based on whether the
minimum value of the criterion function is statistically different from
0. In the point identified case, this is the well known GMM
overidentification test [@hansen1982e]. Here, we implement it
via bootstrapping as discussed by @hallhorowitz1996e, because the
moments depend on the estimated propensity score which is estimated in a
first stage. In the partially identified case, we implement the
misspecification test discussed by @bugnicanayshi2015joe. The
specification tests are automatically conducted when
bootstraps is positive and the minimum criterion value in
the sample problem is larger than 0. However, it can be turned off by
setting specification.test = FALSE.
args <- list(data = ivmteSimData,
ivlike = y ~ d + factor(z),
target = "ate",
m0 = ~ u,
m1 = ~ u,
m0.dec = TRUE,
m1.dec = TRUE,
propensity = d ~ factor(z),
bootstraps = 50)
r <- do.call(ivmte, args)
#> Warning: MTR is point identified via GMM. Shape constraints are ignored.
summary(r)
#>
#> Point estimate of the target parameter: -0.5389508
#> MTR coefficients: 4
#> Independent/total moments: 5/5
#>
#> Bootstrapped confidence intervals (nonparametric):
#> 90%: [-0.6085175, -0.4937168]
#> 95%: [-0.6122408, -0.4929158]
#> 99%: [-0.6282604, -0.4765259]
#> p-value: 0
#> Bootstrapped J-test p-value: 0.32
#> Number of bootstraps: 50
args[["ivlike"]] <- y ~ d + factor(z) + d*factor(z) # many more moments
args[["point"]] <- TRUE
r <- do.call(ivmte, args)
#> Warning: If argument 'point' is set to TRUE, then shape restrictions on m0 and
#> m1 are ignored, and the audit procedure is not implemented.
summary(r)
#>
#> Point estimate of the target parameter: -0.5559325
#> MTR coefficients: 4
#> Independent/total moments: 8/8
#>
#> Bootstrapped confidence intervals (nonparametric):
#> 90%: [-0.6009581, -0.5048528]
#> 95%: [-0.605144, -0.5039834]
#> 99%: [-0.6100535, -0.501858]
#> p-value: 0
#> Bootstrapped J-test p-value: 0.52
#> Number of bootstraps: 50After the estimation procedure, the MTR and MTE functions can be plotted for for further analysis. Below is a demonstration of how to generate such plots when the MTR functions contain splines.
args <- list(data = AE,
ivlike = worked ~ morekids + samesex + morekids*samesex,
target = "att",
m0 = ~ 0 + uSplines(degree = 2, knots = c(1/3, 2/3)),
m1 = ~ 0 + uSplines(degree = 2, knots = c(1/3, 2/3)),
m1.inc = TRUE,
m0.inc = TRUE,
mte.dec = TRUE,
propensity = morekids ~ samesex)
r <- do.call(ivmte, args)
r
#>
#> Bounds on the target parameter: [-0.08484221, 0.08736006]
#> Audit terminated successfully after 2 roundsThe specification of each uniquely defined spline is stored in the
list r$splines.dict. For example, if m0
contained only the terms uSplines(degree = 0, knots = 0.5)
and x:uSplines(degree = 0, knots = 0.5), then the list
r$splines.dict$m0 will contain a single entry, since the
two terms above contain the same spline.
specs0 <- r$splines.dict$m0[[1]]
specs0
#> $degree
#> [1] 2
#>
#> $intercept
#> [1] TRUE
#>
#> $knots
#> [1] 0.3333333 0.6666667
#>
#> $gstar.index
#> [1] 1Since the splines must be constructed as part of the estimation
procedure, the variable names for the basis splines are automatically
generated according to a naming convention to ensure that each
coefficient can be mapped to the correct basis. For example, consider
the coefficient estimates for m0 corresponding to the lower
bound on the treatment effect, which are stored in
r$gstar.coef$min.g0
r$gstar.coef$min.g0
#> [m0]u0S1.1:1 [m0]u0S1.2:1 [m0]u0S1.3:1 [m0]u0S1.4:1 [m0]u0S1.5:1
#> 0.5134883 0.5116711 0.5855708 0.5917033 0.5913861u0S,
indicate that the variables corresponds to a spline in m0.
A basis splines in m1 would instead be assigned a name
beginning with u1S.r$splines.dict is the
one with the same index in r$splines.dict$gstar.index. This
is required to differentiate between splines with the same number of
basis functions.For example, u0S1.4:1 refers to the fourth basis
function of the first spline in m0; whereas
u1S2.2:x refers to the second basis function of the second
spline in m1, interacted with the variable
x.
To plot the MTR, users simply need to construct the appropriate
design matrix and multiply it with the coefficient estimates. Below, a
design matrix for m0 for a grid of 101 points over the unit
interval is constructed using the command bSpline from the
splines2 package. While ivmte assumes the
boundary knots are always 0 and 1, the user will have to explicitly
declare the boundary knots when using the bSpline command.
Multiplying the design matrix by r$gstar.coef$min.g0
generates the fitted values for m0 associated with the
lower bound of the treatment effect. Likewise, multiplying the design
matrix by r$gstar.coef$max.g0 generates the fitted values
for m0 associated with the upper bound.
uSeq <- seq(0, 1, by = 0.01)
dmat0 <- bSpline(x = uSeq,
degree = specs0$degree,
intercept = specs0$intercept,
knots = specs0$knots,
Boundary.knots = c(0, 1))
m0.min <- dmat0 %*% r$gstar.coef$min.g0
m0.max <- dmat0 %*% r$gstar.coef$max.g0The analogous steps can be performed to obtain the fitted values for
m1. Taking the difference of the fitted values for
m1 and m0 yields an MTE curve. However, unless
there is point identification, the MTR and MTE curves are optimal but
not unique. That is, the curves either maximize or minimize the
treatment effect parameter, but there are other MTR and MTE curves that
are observationally equivalent and yield the same maximal or minimal
value of the treatment effect.
Below are plots of the MTR and MTE as functions of unobserved
heterogeneity u. The figures on the left correspond to the
lower bound of the treatment effect, and the figures on the right
correspond to the upper bound.
mte.min <- m1.min - m0.min
mte.max <- m1.max - m0.max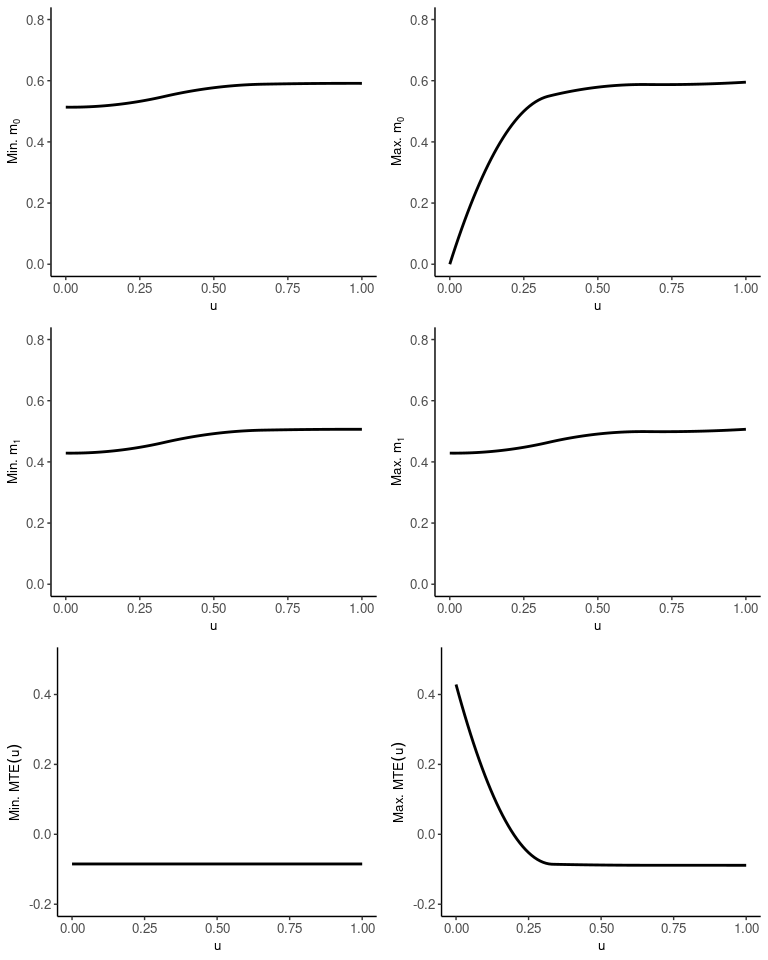
In the case of the MTE associated with the lower bound, the
monotonicity constraints are all binding, resulting in a constant MTE.
If the plots do not satisfy all the shape constraints, this implies the
audit grid is not large enough, and that audit.nu should be
increased.
This section presents an example of how to plot the average weights associated with the target parameter and IV-like estimands, which may be of interest to the user.
Continuing with the model specification from the previous section,
information on the target weights for the treated individuals are stored
in the list r$gstar.weights$w1, and the target weights for
the untreated are stored in the list r$gstar.weights$w0.
These lists contain three entries:
$lb: A vector of the lower bounds for the values of
u where the weight is not 0.$ub: A vector of the upper bounds for the values of
u where the weight is not 0.$multiplier: A vector of the weights assigned to agents
with u between $lb and $ub.The values of $lb and $ub are obtained from
an agent’s propensity to take up treatment. The weight assigned to
agents outside of that interval is 0.
The list r$s.set contains all the information from the
IV-like estimands, including the treated and untreated weights.
Information relevant to the first estimand is stored in the list
r$s.set$s1$; information relevant to the second estimand is
stored in the list r$s.set$s2, and so on. The weights for
the first estimand are contained in r$s.set$s1$w0 and
r$s.set$s1$w1, both of which are lists that take the same
structure as described earlier for r$gstar.weights$w0 and
r$gstar.weights$w1.
Below, the treated weights for the target parameter and IV-like estimands are organized into matrices with columns for the lower bound, upper bound, and multiplier.
## Target weights
w1 <- cbind(r$gstar.weights$w1$lb,
r$gstar.weights$w1$ub,
r$gstar.weights$w1$multiplier)
## IV-like estimand weights
sw1 <- cbind(r$s.set$s1$w1$lb,
r$s.set$s1$w1$ub,
r$s.set$s1$w1$multiplier)
sw2 <- cbind(r$s.set$s2$w1$lb,
r$s.set$s2$w1$ub,
r$s.set$s2$w1$multiplier)
sw3 <- cbind(r$s.set$s3$w1$lb,
r$s.set$s3$w1$ub,
r$s.set$s3$w1$multiplier)
sw4 <- cbind(r$s.set$s4$w1$lb,
r$s.set$s4$w1$ub,
r$s.set$s4$w1$multiplier)
## Assign column names
colnames(w1) <-
colnames(sw1) <-
colnames(sw2) <-
colnames(sw3) <-
colnames(sw4) <- c("lb", "ub", "mp")Since the propensity score model is simply
morekids ~ samesex, and samesex is a binary
variable, there are only two values of the propensity score. These two
values partition the unit interval into three regions, and the average
weights will vary across these three regions. These propensity scores
can be recovered from the column ub in any of the matrices
constructed above.
pscore <- sort(unique(w1[, "ub"]))
pscore
#> [1] 0.3021445 0.3610127More generally, the propensity scores determine the upper bound for the region where the weights are non-zero for the treated weights associated with the IV-like estimands. In the case of the untreated weights associated with the IV-like estimands, the propensity score determines the lower bound.
The code below demonstrates how to calculate the average weights for
each interval, and stores the results in a data.frame that
will be used to generate the plot. The analogous calculations can be
performed to estimate the average weights for the untreated agents.
avg1 <- NULL ## The data.frame that will contain the average weights
i <- 0 ## An index for the type of weight
for (j in c('w1', 'sw1', 'sw2', 'sw3', 'sw4')) {
dt <- data.frame(get(j))
avg <- rbind(
## Average for u in [0, pscore[1])
c(s = i, d = 1, lb = 0, ub = pscore[1],
avgWeight = mean(dt$mp)),
## Average for u in [pscore[1], pscore[2])
c(s = i, d = 1, lb = pscore[1], ub = pscore[2],
avgWeight = mean(as.integer(dt$ub ==
pscore[2]) * dt$mp)),
## Average for u in [pscore[2], 1]
c(s = i, d = 1, lb = pscore[2], ub = 1, avgWeight = 0))
avg1 <- rbind(avg1, avg)
i <- i + 1
}
avg1 <- data.frame(avg1)[0, pscore[1]), contains agents who
take up treatment regardless of whether samesex = FALSE or
samesex = TRUE. The average weight can therefore be
estimated simply by taking the average of the weights assigned to each
agent.[pscore[1], pscore[2]), contains
agents who would take up treatment if samesex = TRUE, but
would not take up treatment if samesex = FALSE. The weights
for agents with samesex = FALSE are thus 0 is in this
region.[pscore[2], 1], contains
agents who will not take up treatment regardless of the value of
samesex. Since the object of interest is the weights of the
treated agents, the average weight in this third region is necessarily
0.The data.frame created above that will be used to
generate the plot for the average treated weights takes on the following
form.
| s | d | lb | ub | avgWeight |
|---|---|---|---|---|
| 0 | 1 | 0.0000000 | 0.3021445 | 3.0124888 |
| 0 | 1 | 0.3021445 | 0.3610127 | 1.5253234 |
| 0 | 1 | 0.3610127 | 1.0000000 | 0.0000000 |
| 1 | 1 | 0.0000000 | 0.3021445 | 0.0000000 |
| 1 | 1 | 0.3021445 | 0.3610127 | 0.0000000 |
| 1 | 1 | 0.3610127 | 1.0000000 | 0.0000000 |
| 2 | 1 | 0.0000000 | 0.3021445 | 3.3096749 |
| 2 | 1 | 0.3021445 | 0.3610127 | 0.0000000 |
| 2 | 1 | 0.3610127 | 1.0000000 | 0.0000000 |
| 3 | 1 | 0.0000000 | 0.3021445 | 0.0000000 |
| 3 | 1 | 0.3021445 | 0.3610127 | 0.0000000 |
| 3 | 1 | 0.3610127 | 1.0000000 | 0.0000000 |
| 4 | 1 | 0.0000000 | 0.3021445 | -0.5396896 |
| 4 | 1 | 0.3021445 | 0.3610127 | 2.7699854 |
| 4 | 1 | 0.3610127 | 1.0000000 | 0.0000000 |
0 indicates the weight corresponds to the target parameter.
Integers greater than 0 indicate the weight corresponds to the IV-like
estimand with the same index.Adjusting for overlaps, the table above generates the plot below on the right. The analogous table containing the average untreated weights generates the plot on the left. For clarity, the weights for associated with the intercept have been omitted from both plots.
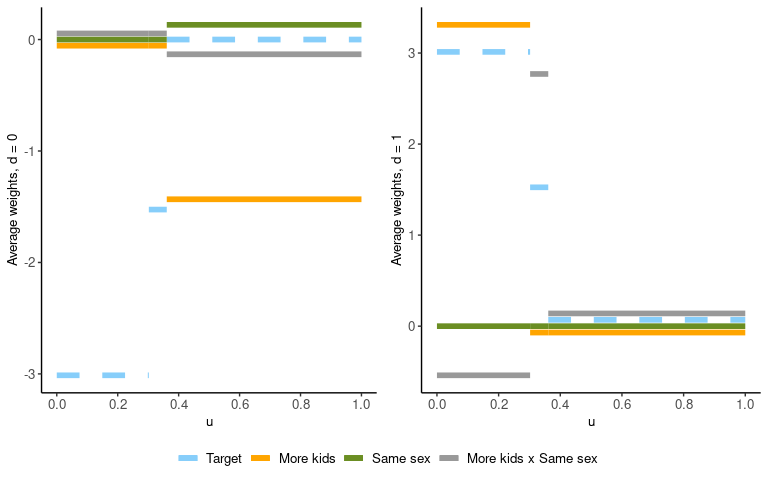
Please post an issue on the GitHub repository.
These binaries (installable software) and packages are in development.
They may not be fully stable and should be used with caution. We make no claims about them.
Health stats visible at Monitor.