The hardware and bandwidth for this mirror is donated by dogado GmbH, the Webhosting and Full Service-Cloud Provider. Check out our Wordpress Tutorial.
If you wish to report a bug, or if you are interested in having us mirror your free-software or open-source project, please feel free to contact us at mirror[@]dogado.de.
![]()
El paquete itan tiene como finalidad ayudar a profesores a corregir, calificar y analizar pruebas objetivas. Para ello, este paquete incluye funciones que permiten calcular el puntaje y calificación obtenido por estudiantes; así como también, funciones para analizar los ítems del test. Entre estas últimas destaca el análisis gráfico de ítems que permite visualizar las características técnicas del ítem y determinar rápidamente su calidad.
Para instalar la versión de desarrollo del paquete itan desde GitHub use el siguiente comando:
# install.packages("devtools")
devtools::install_github("arielarmijo/itan")
library(itan)El paquete itan incluye dos datos binarios de ejemplo llamados datos y clave. Datos contiene las respuestas de 39 estudiantes a una prueba de 50 ítems y clave contiene las respuestas correctas a cada ítem.
data(datos, clave)
str(datos, list.len=6)
#> 'data.frame': 39 obs. of 51 variables:
#> $ id : int 200040629 210047876 210047897 210040939 200035827 200039332 200040360 210047865 210046146 210045972 ...
#> $ i01: chr "E" "C" "E" "E" ...
#> $ i02: chr "D" "D" "D" "D" ...
#> $ i03: chr "C" "C" "C" "A" ...
#> $ i04: chr "B" "B" "B" "B" ...
#> $ i05: chr "A" "C" "A" "A" ...
#> [list output truncated]
str(clave, list.len=5)
#> 'data.frame': 1 obs. of 50 variables:
#> $ i01: chr "E"
#> $ i02: chr "D"
#> $ i03: chr "C"
#> $ i04: chr "B"
#> $ i05: chr "A"
#> [list output truncated]Para calcular el puntaje alcanzado en la prueba y su respectiva calificación puede usarse el siguiente script:
respuestas <- datos[,-1]
respuestasCorregidas <- corregirRespuestas(respuestas, clave)
head(respuestasCorregidas)
#> i01 i02 i03 i04 i05 i06 i07 i08 i09 i10 i11 i12 i13 i14 i15 i16 i17 i18 i19
#> 1 1 1 1 1 1 1 1 0 0 0 0 1 1 1 1 1 1 1 1
#> 2 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 1 0 1 1
#> 3 1 1 1 1 1 1 0 0 0 1 1 1 0 0 1 1 0 1 1
#> 4 1 1 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 1
#> 5 0 0 0 0 0 0 0 0 1 1 1 1 1 0 0 0 0 0 0
#> 6 1 1 1 0 1 1 1 0 0 1 1 1 0 0 0 1 0 0 0
#> i20 i21 i22 i23 i24 i25 i26 i27 i28 i29 i30 i31 i32 i33 i34 i35 i36 i37 i38
#> 1 1 1 1 0 0 1 0 1 0 1 0 1 1 1 1 1 1 1 0
#> 2 0 0 0 0 1 0 0 0 0 0 0 1 1 0 0 1 1 0 1
#> 3 0 0 0 0 0 1 1 1 0 1 1 0 1 0 1 1 0 1 0
#> 4 0 1 1 0 1 0 0 0 0 1 0 0 1 1 1 1 0 1 1
#> 5 0 0 0 0 0 0 0 0 1 1 0 1 1 1 1 1 1 1 1
#> 6 0 0 1 0 0 0 1 0 0 1 0 0 1 1 0 1 0 0 0
#> i39 i40 i41 i42 i43 i44 i45 i46 i47 i48 i49 i50
#> 1 1 1 1 1 0 1 1 0 0 1 1 1
#> 2 1 0 0 0 1 1 1 0 1 0 0 0
#> 3 1 1 1 0 1 1 1 1 0 0 0 1
#> 4 1 1 1 1 1 1 1 0 1 1 1 1
#> 5 1 1 1 0 1 0 0 1 0 0 0 0
#> 6 1 0 0 1 0 0 0 0 0 0 0 1
puntaje <- calcularPuntajes(respuestasCorregidas)
nota <- calcularNotas(puntaje)
head(cbind(id=datos$id, puntaje, nota))
#> id puntaje nota
#> 1 200040629 37 6.0
#> 2 210047876 17 3.0
#> 3 210047897 30 4.7
#> 4 210040939 30 4.7
#> 5 200035827 20 3.3
#> 6 200039332 19 3.2Además de calcular el puntaje y calificación, es posible analizar los ítems de la prueba. Para calcular el índice de dificultad y los índices de discriminación de cada ítem se puede ejecutar las siguientes líneas de código:
p <- calcularIndiceDificultad(respuestasCorregidas, proporcion = 0.25)
dc1 <- calcularIndiceDiscriminacion(respuestasCorregidas, tipo = "dc1", proporcion = 0.25)
dc2 <- calcularIndiceDiscriminacion(respuestasCorregidas, tipo = "dc2", proporcion = 0.25)
head(cbind(p, dc1, dc2))
#> p dc1 dc2
#> i01 0.75 0.3 0.60
#> i02 0.95 -0.1 0.47
#> i03 0.60 0.0 0.50
#> i04 0.60 0.6 0.75
#> i05 0.55 0.7 0.82
#> i06 0.70 0.2 0.57Otra manera de analizar la discriminación de un ítem es usando el coeficiente de correlación biserial puntual:
alternativas <- c(LETTERS[1:5], "*")
biserial <- pBis(respuestas, clave, alternativas)
head(biserial)
#> item A B C D E * KEY
#> 1 i01 -0.23 -0.09 -0.14 -0.03 0.25 -0.17 E
#> 2 i02 NaN -0.10 0.09 -0.10 NaN -0.05 D
#> 3 i03 0.02 -0.15 -0.05 -0.12 NaN 0.10 C
#> 4 i04 -0.34 0.34 NaN -0.13 -0.16 -0.05 B
#> 5 i05 0.55 -0.36 -0.39 NaN -0.12 -0.05 A
#> 6 i06 -0.19 0.01 0.16 -0.17 -0.10 -0.17 CLa frecuencia con que se eligió cada alternativa en cada ítem puede hacerse de forma numérica o gráfica:
fa <- calcularFrecuenciaAlternativas(respuestas, alternativas, clave, frecuencia = FALSE)
head(fa)
#> item A B C D E * NA KEY
#> 1 i01 6 4 4 2 21 2 0 E
#> 2 i02 0 1 4 33 0 1 0 D
#> 3 i03 6 4 26 1 0 2 0 C
#> 4 i04 13 22 0 2 1 1 0 B
#> 5 i05 17 8 6 0 7 1 0 A
#> 6 i06 2 6 25 3 1 2 0 Cgfa <- graficarFrecuenciaAlternativas(respuestas, alternativas, clave)
gfa$i01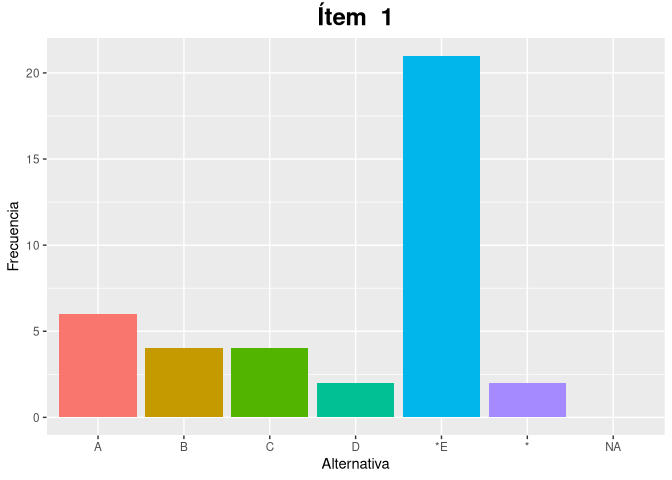
El paquete itan también implementa el análisis gráfico de ítems que permite resumir las características técnicas del ítem de manera visual, lo que facilita su análisis:
item <- agi(respuestas, clave, alternativas)
item$i01$plot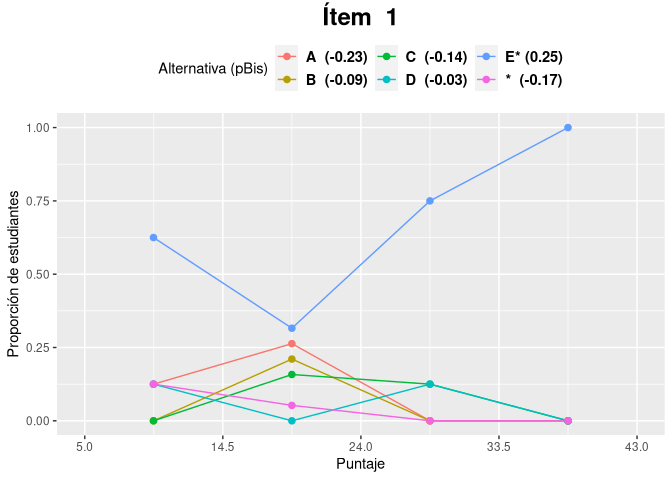
Revisar la documentación del paquete para ver más detalles sobre las funciones anteriormente señaladas.
These binaries (installable software) and packages are in development.
They may not be fully stable and should be used with caution. We make no claims about them.
Health stats visible at Monitor.