The hardware and bandwidth for this mirror is donated by dogado GmbH, the Webhosting and Full Service-Cloud Provider. Check out our Wordpress Tutorial.
If you wish to report a bug, or if you are interested in having us mirror your free-software or open-source project, please feel free to contact us at mirror[@]dogado.de.
This repository contains an R package allowing to build
Paragraph Vector models also known as doc2vec
models. You can train the distributed memory (‘PV-DM’) and the
distributed bag of words (‘PV-DBOW’) models. Next to that, it also
allows to build a top2vec model allowing to cluster
documents based on these embeddings.
install.packages("doc2vec")remotes::install_github("bnosac/doc2vec")Look to the documentation of the functions
help(package = "doc2vec")library(doc2vec)
library(tokenizers.bpe)
library(udpipe)
data(belgium_parliament, package = "tokenizers.bpe")
x <- subset(belgium_parliament, language %in% "dutch")
x <- data.frame(doc_id = sprintf("doc_%s", 1:nrow(x)),
text = x$text,
stringsAsFactors = FALSE)
x$text <- tolower(x$text)
x$text <- gsub("[^[:alpha:]]", " ", x$text)
x$text <- gsub("[[:space:]]+", " ", x$text)
x$text <- trimws(x$text)
x$nwords <- txt_count(x$text, pattern = " ")
x <- subset(x, nwords < 1000 & nchar(text) > 0)## Low-dimensional model using DM, low number of iterations, for speed and display purposes
model <- paragraph2vec(x = x, type = "PV-DM", dim = 5, iter = 3,
min_count = 5, lr = 0.05, threads = 1)
str(model)## List of 3
## $ model :<externalptr>
## $ data :List of 4
## ..$ file : chr "C:\\Users\\Jan\\AppData\\Local\\Temp\\Rtmpk9Npjg\\textspace_1c446bffa0e.txt"
## ..$ n : num 170469
## ..$ n_vocabulary: num 3867
## ..$ n_docs : num 1000
## $ control:List of 9
## ..$ min_count: int 5
## ..$ dim : int 5
## ..$ window : int 5
## ..$ iter : int 3
## ..$ lr : num 0.05
## ..$ skipgram : logi FALSE
## ..$ hs : int 0
## ..$ negative : int 5
## ..$ sample : num 0.001
## - attr(*, "class")= chr "paragraph2vec_trained"## More realistic model
model <- paragraph2vec(x = x, type = "PV-DBOW", dim = 100, iter = 20,
min_count = 5, lr = 0.05, threads = 4)embedding <- as.matrix(model, which = "words")
embedding <- as.matrix(model, which = "docs")
vocab <- summary(model, which = "docs")
vocab <- summary(model, which = "words")sentences <- list(
sent1 = c("geld", "diabetes"),
sent2 = c("frankrijk", "koning", "proximus"))
embedding <- predict(model, newdata = sentences, type = "embedding")
embedding <- predict(model, newdata = c("geld", "koning"), type = "embedding", which = "words")
embedding <- predict(model, newdata = c("doc_1", "doc_10", "doc_3"), type = "embedding", which = "docs")
ncol(embedding)## [1] 100embedding[, 1:4]## [,1] [,2] [,3] [,4]
## doc_1 0.05721277 -0.10298843 0.1089350 -0.03075439
## doc_10 0.09553983 0.05211980 -0.0513489 -0.11847925
## doc_3 0.08008177 -0.03324692 0.1563442 0.06585038nn <- predict(model, newdata = c("proximus", "koning"), type = "nearest", which = "word2word", top_n = 5)
nn## [[1]]
## term1 term2 similarity rank
## 1 proximus telefoontoestellen 0.5357178 1
## 2 proximus belfius 0.5169221 2
## 3 proximus ceo 0.4839031 3
## 4 proximus klanten 0.4819543 4
## 5 proximus taal 0.4590944 5
##
## [[2]]
## term1 term2 similarity rank
## 1 koning ministerie 0.5615162 1
## 2 koning verplaatsingen 0.5484987 2
## 3 koning familie 0.4911003 3
## 4 koning grondwet 0.4871097 4
## 5 koning gedragen 0.4694150 5nn <- predict(model, newdata = c("proximus", "koning"), type = "nearest", which = "word2doc", top_n = 5)
nn## [[1]]
## term1 term2 similarity rank
## 1 proximus doc_105 0.6684639 1
## 2 proximus doc_863 0.5917463 2
## 3 proximus doc_186 0.5233522 3
## 4 proximus doc_620 0.4919243 4
## 5 proximus doc_862 0.4619178 5
##
## [[2]]
## term1 term2 similarity rank
## 1 koning doc_44 0.6686417 1
## 2 koning doc_45 0.5616031 2
## 3 koning doc_583 0.5379452 3
## 4 koning doc_943 0.4855201 4
## 5 koning doc_797 0.4573555 5nn <- predict(model, newdata = c("doc_198", "doc_285"), type = "nearest", which = "doc2doc", top_n = 5)
nn## [[1]]
## term1 term2 similarity rank
## 1 doc_198 doc_343 0.5522854 1
## 2 doc_198 doc_899 0.4902798 2
## 3 doc_198 doc_983 0.4847047 3
## 4 doc_198 doc_642 0.4829021 4
## 5 doc_198 doc_336 0.4674844 5
##
## [[2]]
## term1 term2 similarity rank
## 1 doc_285 doc_319 0.5318567 1
## 2 doc_285 doc_286 0.5100293 2
## 3 doc_285 doc_113 0.5056069 3
## 4 doc_285 doc_526 0.4840761 4
## 5 doc_285 doc_488 0.4805686 5sentences <- list(
sent1 = c("geld", "frankrijk"),
sent2 = c("proximus", "onderhandelen"))
nn <- predict(model, newdata = sentences, type = "nearest", which = "sent2doc", top_n = 5)
nn## $sent1
## term1 term2 similarity rank
## 1 sent1 doc_742 0.4830917 1
## 2 sent1 doc_151 0.4340138 2
## 3 sent1 doc_825 0.4263285 3
## 4 sent1 doc_740 0.4059283 4
## 5 sent1 doc_776 0.4024554 5
##
## $sent2
## term1 term2 similarity rank
## 1 sent2 doc_105 0.5497447 1
## 2 sent2 doc_863 0.5061581 2
## 3 sent2 doc_862 0.4973840 3
## 4 sent2 doc_620 0.4793786 4
## 5 sent2 doc_186 0.4755909 5sentences <- strsplit(setNames(x$text, x$doc_id), split = " ")
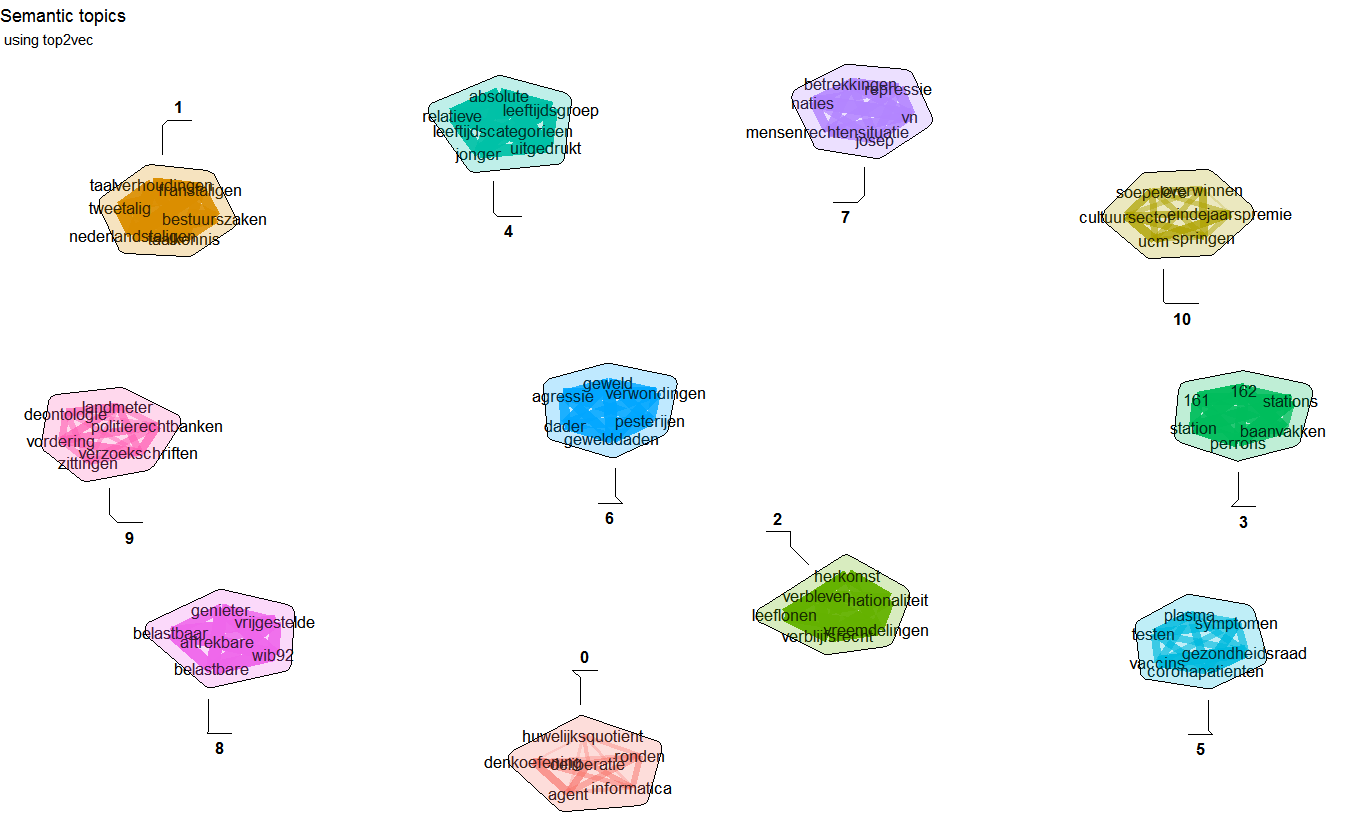
nn <- predict(model, newdata = sentences, type = "nearest", which = "sent2doc", top_n = 5)Top2vec clusters document semantically and finds most semantically relevant terms for each topic
library(doc2vec)
library(word2vec)
library(uwot)
library(dbscan)
data(be_parliament_2020, package = "doc2vec")
x <- data.frame(doc_id = be_parliament_2020$doc_id,
text = be_parliament_2020$text_nl,
stringsAsFactors = FALSE)
x$text <- txt_clean_word2vec(x$text)
x <- subset(x, txt_count_words(text) < 1000)
d2v <- paragraph2vec(x, type = "PV-DBOW", dim = 50,
lr = 0.05, iter = 10,
window = 15, hs = TRUE, negative = 0,
sample = 0.00001, min_count = 5,
threads = 1)
model <- top2vec(d2v,
control.dbscan = list(minPts = 50),
control.umap = list(n_neighbors = 15L, n_components = 3), umap = tumap,
trace = TRUE)
info <- summary(model, top_n = 7)
info$topwordsThe package has some hard limits namely
Need support in text mining? Contact BNOSAC: http://www.bnosac.be
These binaries (installable software) and packages are in development.
They may not be fully stable and should be used with caution. We make no claims about them.
Health stats visible at Monitor.