The hardware and bandwidth for this mirror is donated by dogado GmbH, the Webhosting and Full Service-Cloud Provider. Check out our Wordpress Tutorial.
If you wish to report a bug, or if you are interested in having us mirror your free-software or open-source project, please feel free to contact us at mirror[@]dogado.de.
![]()
![]()
![]()


![]()
![]()

![]()
ACEP es un paquete de funciones en lenguaje R útiles para la detección y el análisis de eventos de protesta en corpus de textos periodísticos. Sus funciones son aplicables a cualquier corpus de textos. Ademas de las funciones, ACEP contiene también bases de datos con colecciones de notas sobre protestas y una colección de diccionarios de palabras conflictivas y otros tópicos referidos a diferentes aspectos del análisis de eventos de protesta.
La versión estable actual de ACEP es 0.1.1 y se instala
desde CRAN
con:
install.packages("ACEP")Puedes instalar la versión de desarrollo de ACEP desde GitHub con:
# install.packages("devtools")
devtools::install_github("agusnieto77/ACEP")ACEP mantiene una instalación base liviana. Las funciones principales de limpieza, conteo, diccionarios, series temporales y proveedores LLM HTTP/JSON se instalan con las dependencias obligatorias del paquete.
Algunas funciones de NLP, etiquetado gramatical y geocodificación
requieren paquetes opcionales. Si vas a usar acep_postag(),
acep_postag_hibrido(), acep_upos() o flujos
que dependan de esas capacidades, instalá los paquetes necesarios
con:
install.packages(c("spacyr", "reticulate", "rsyntax", "tidygeocoder", "udpipe"))Si falta una dependencia opcional, ACEP muestra un mensaje indicando qué paquete instalar para esa funcionalidad.
| Nombre | Ciclo | Descripción |
|---|---|---|
acep_clean() |
 |
Limpieza de texto. |
acep_claude() |
|
Función para interactuar con modelos Anthropic Claude. |
acep_clear_regex_cache() |
|
Limpia la caché de expresiones regulares compiladas. |
acep_context() |
|
Función para extraer contexto de palabras o frases. |
acep_corpus() |
|
Constructor de objetos acep_corpus para pipelines. |
acep_count() |
 |
Frecuencia de menciones de palabras. |
acep_db() |
|
Frecuencia, menciones e intensidad. |
acep_detect() |
|
Detección de menciones de palabras. |
acep_extract() |
|
Extraer palabras de un texto. |
acep_frec() |
|
Frecuencia de palabras totales. |
acep_gemini() |
|
Función para interactuar con modelos Google Gemini. |
acep_gpt() |
|
Función para interactuar con modelos OpenAI GPT. |
acep_gpt_schema() |
|
Define esquemas para respuestas estructuradas de GPT. |
acep_int() |
|
Índice de intensidad. |
acep_load_base() |
|
Carga bases de datos creadas por el Observatorio. |
acep_may() |
|
Convierte el texto a mayúsculas. |
acep_min() |
|
Convierte el texto a minúsculas. |
acep_ollama() |
|
Función para interactuar con modelos Ollama locales. |
acep_ollama_setup() |
|
Configuración y verificación del entorno Ollama. |
acep_openrouter() |
|
Función para interactuar con 400+ modelos vía OpenRouter. |
acep_pipeline() |
|
Pipeline composable para procesamiento de texto. |
acep_plot_rst() |
|
Resumen visual de la serie temporal de los índices de conflictividad. |
acep_plot_st() |
|
Gráfico de barras de la serie temporal de índices de conflictividad. |
acep_postag() |
|
Función para etiquetado POS, lematización, tokenización, extracción de entidades. |
acep_postag_hibrido() |
|
Etiquetado POS híbrido combinando udpipe y spacyr. |
acep_process_chunks() |
|
Procesamiento de textos en chunks para optimizar memoria. |
acep_regex_cache_size() |
|
Consulta el tamaño actual de la caché de regex. |
acep_result() |
|
Constructor de objetos acep_result para resultados de análisis. |
acep_sst() |
|
Serie temporal de índices de conflictividad. |
acep_svo() |
|
Función para extraer tripletes SVO (Sujeto-Verbo-Objeto). |
acep_together() |
|
Función para interactuar con modelos TogetherAI mediante JSON mode o texto libre. |
acep_token() |
|
Función para tokenizar. |
acep_token_plot() |
|
Gráfico de barras de palabras más recurrentes en un corpus. |
acep_token_table() |
|
Tabla de frecuencia de palabras tokenizadas. |
acep_upos() |
|
Función para etiquetado POS, lematización, tokenización. |
pipe_clean() |
|
Pipeline: limpieza de texto. |
pipe_count() |
|
Pipeline: conteo de menciones. |
pipe_intensity() |
|
Pipeline: cálculo de intensidad. |
pipe_timeseries() |
|
Pipeline: series temporales. |
| Nombre | Descripción |
|---|---|
acep_bases |
Colección de notas y recursos de prueba
(incluye la muestra etiquetada lc_720). |
acep_diccionarios |
Colección de diccionarios. |
acep_prompt_gpt |
Colección de instrucciones. |
acep_rs |
Cadenas de caracteres para limpiar y normalizar textos. |
![]() Colección de notas del diario La
Nación
Colección de notas del diario La
Nación
![]() Subset de notas del diario La
Nación
Subset de notas del diario La
Nación
![]() Colección de notas del Ecos
Diarios
Colección de notas del Ecos
Diarios
![]() Colección de notas de la Revista
Puerto
Colección de notas de la Revista
Puerto
![]() Colección de notas del diario La
Nueva
Colección de notas del diario La
Nueva
![]() Colección de notas del diario La
Capital
Colección de notas del diario La
Capital
ACLED: Armed Conflict Location & Event Data Project.
GDELT: The GDELT Project About.
GPT: Global Protest Tracker.
MMPD: Mass Mobilization Protest Data Project.
NAVCO: Nonviolent and Violent Campaigns and Outcomes data project.
NVCO: Global Nonviolent Action Database.
SCAD: Social Conflict Analysis Database.
SPEED: The Social, Political and Economic Event Database Project.
UCDP: Uppsala Conflict Data Program.
FMI: FMI Data.
BM: Datos de libre acceso del Banco Mundial.
OIT: Estadísticas y bases de datos.
CEPAL: Datos y estadísticas.
DARG: Datos abiertos de Argentina.
MGP: Datos abiertos del Municipio de Gral. Pueyrredon, Buenos Aires, Argentina.
# Cargamos la librería
require(ACEP)
# Cargamos la base de notas de la Revista Puerto con la función acep_load_base()
rev_puerto <- acep_load_base(acep_bases$rp_mdp)
# Cargamos el diccionario de conflictos de SISMOS
dicc_confl_sismos <- acep_diccionarios$dicc_confl_sismos
# Con la función acep_frec() contamos la frecuencia de palabras de cada nota
# y creamos una nueva columna llamada n_palabras
rev_puerto$n_palabras <- acep_frec(rev_puerto$nota)
# Imprimimos en pantalla la base con la nueva columna de frecuencia de palabras
head(rev_puerto)#> # A tibble: 6 × 7
#> fecha titulo bajada nota imagen link n_palabras
#> <date> <chr> <chr> <chr> <chr> <chr> <int>
#> 1 2020-12-29 ¡Feliz Año 2021 para todos nu… Con m… "Con… https… http… 28
#> 2 2020-12-28 Mapa del trabajo esclavo en a… Un re… "El … https… http… 1142
#> 3 2020-12-24 Plantas piden tener garantiza… En Ch… "El … https… http… 536
#> 4 2020-12-24 Los obreros navales despiden … En Ma… "El … https… http… 489
#> 5 2020-12-23 El incumplimiento del régimen… Se ll… "Las… https… http… 529
#> 6 2020-12-23 Otro fallo ratifica cautelar … La Cá… "La … https… http… 467# Ahora con la función acep_count() contamos la frecuencia de menciones de
# términos del diccionario de conflictividad de SISMOS de cada nota y
# creamos una nueva columna llamada conflictos.
# Elaboramos un corpus acotado para el ejemplo
rev_puerto <- rev_puerto[1:100, ]
rev_puerto$conflictos <- acep_count(rev_puerto$nota, dicc_confl_sismos)
# Imprimimos en pantalla la base con la nueva columna de
# menciones del diccionario de conflictividad
head(rev_puerto)#> # A tibble: 6 × 8
#> fecha titulo bajada nota imagen link n_palabras conflictos
#> <date> <chr> <chr> <chr> <chr> <chr> <int> <int>
#> 1 2020-12-29 ¡Feliz Año 2021 pa… Con m… "Con… https… http… 28 0
#> 2 2020-12-28 Mapa del trabajo e… Un re… "El … https… http… 1142 0
#> 3 2020-12-24 Plantas piden tene… En Ch… "El … https… http… 536 0
#> 4 2020-12-24 Los obreros navale… En Ma… "El … https… http… 489 0
#> 5 2020-12-23 El incumplimiento … Se ll… "Las… https… http… 529 0
#> 6 2020-12-23 Otro fallo ratific… La Cá… "La … https… http… 467 0# Ahora con la función acep_int() calculamos un índice de intensidad de
# la conflictividad y creamos una nueva columna llamada intensidad
rev_puerto$intensidad <- acep_int(
rev_puerto$conflictos,
rev_puerto$n_palabras,
3)
# Imprimimos en pantalla la base con la nueva columna de intensidad
head(rev_puerto)#> # A tibble: 6 × 9
#> fecha titulo bajada nota imagen link n_palabras conflictos intensidad
#> <date> <chr> <chr> <chr> <chr> <chr> <int> <int> <dbl>
#> 1 2020-12-29 ¡Feliz … Con m… "Con… https… http… 28 0 0
#> 2 2020-12-28 Mapa de… Un re… "El … https… http… 1142 0 0
#> 3 2020-12-24 Plantas… En Ch… "El … https… http… 536 0 0
#> 4 2020-12-24 Los obr… En Ma… "El … https… http… 489 0 0
#> 5 2020-12-23 El incu… Se ll… "Las… https… http… 529 0 0
#> 6 2020-12-23 Otro fa… La Cá… "La … https… http… 467 0 0# Volvemos a cargar la base de notas de la Revista Puerto sin procesar
rev_puerto <- acep_load_base(acep_bases$rp_mdp)
# Creamos un subset
subset_rp <- rev_puerto[1:100, ]
# Cargamos el diccionario de conflictos de SISMOS
dicc_confl_sismos <- acep_diccionarios$dicc_confl_sismos
# Ahora con la función acep_db() aplicamos las tres funciones en un solo paso
rp_procesada <- acep_db(subset_rp, subset_rp$nota, dicc_confl_sismos, 3)
# Imprimimos en pantalla la base con las tres columna creadas
head(rp_procesada)#> # A tibble: 6 × 9
#> fecha titulo bajada nota imagen link n_palabras conflictos intensidad
#> <date> <chr> <chr> <chr> <chr> <chr> <int> <int> <dbl>
#> 1 2020-12-29 ¡Feliz … Con m… "Con… https… http… 28 0 0
#> 2 2020-12-28 Mapa de… Un re… "El … https… http… 1142 0 0
#> 3 2020-12-24 Plantas… En Ch… "El … https… http… 536 0 0
#> 4 2020-12-24 Los obr… En Ma… "El … https… http… 489 0 0
#> 5 2020-12-23 El incu… Se ll… "Las… https… http… 529 0 0
#> 6 2020-12-23 Otro fa… La Cá… "La … https… http… 467 0 0# Cargamos los datos procesados
rp_procesada <- acep_bases$rp_procesada
# Ahora con la función acep_sst() elaboramos un resumen estadístico
rp_procesada <- acep_sst(rp_procesada, st = "anio", u = 4)
# Imprimimos en pantalla la base con las métricas de conflictividad
head(rp_procesada)#> st frecn csn frecp frecm intac intensidad int_notas_confl
#> 1 2009 632 58 496110 1025 1.2735 0.0021 0.0918
#> 2 2010 680 67 492231 1129 1.6273 0.0023 0.0985
#> 3 2011 601 40 425747 882 1.2204 0.0021 0.0666
#> 4 2012 739 67 564270 1242 1.6841 0.0022 0.0907
#> 5 2013 689 24 525718 758 1.0559 0.0014 0.0348
#> 6 2014 631 30 444823 802 1.2112 0.0018 0.0475# Ahora con la función acep_plot_st() elaboramos un gráfico de barras
# con menciones del diccionario de conflictividad
acep_plot_st(rp_procesada$st, rp_procesada$frecm,
t = "Evolucion de la conflictividad en el sector pesquero argentino",
ejex = "A\u00f1os analizados",
ejey = "Menciones del diccionario de conflictos",
etiquetax = "horizontal")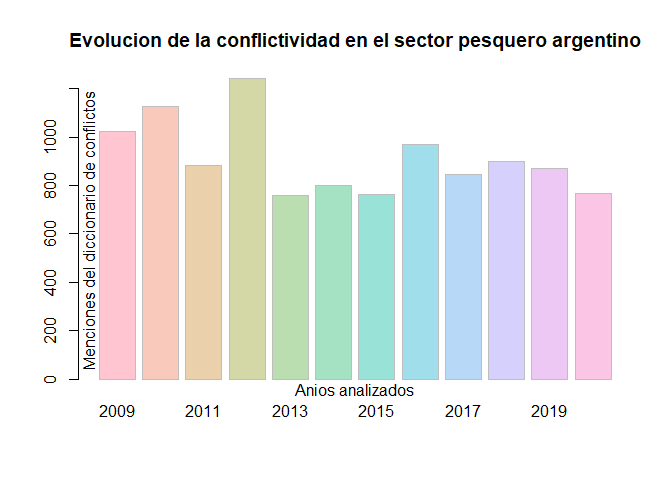
# Ahora con la función acep_plot_rst() elaboramos una visualización resumen.
# con cuatro gráficos de barras
acep_plot_rst(rp_procesada, tagx = "vertical")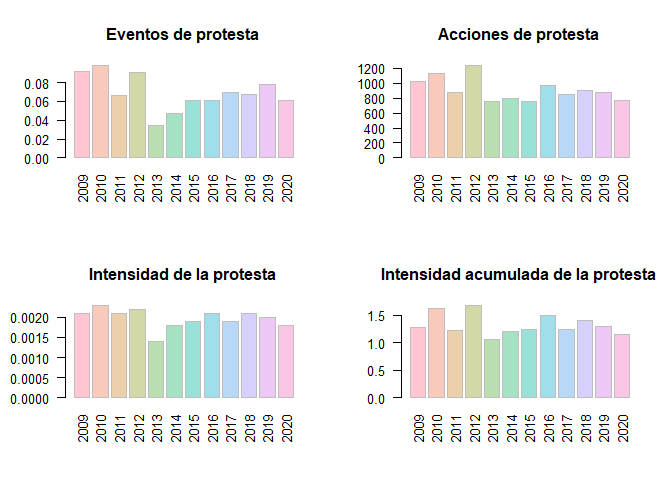
These binaries (installable software) and packages are in development.
They may not be fully stable and should be used with caution. We make no claims about them.
Health stats visible at Monitor.